파이썬 유튜브 영상 정보 다운로드하기 pytube
pytube 예제는 docs기반으로 작성하였습니다.
pytube — pytube 12.1.0 documentation
© Copyright Revision 2e307d8d.
pytube.io
설치
pip install pytube
유튜브 영상 정보 가져오기
# 유튜브 영상정보 가져오기
from pytube import YouTube
url = 'https://youtu.be/TtDeUBKpa6c'
yt = YouTube(url)
print("제목 : ", yt.title)
print("길이 : ", yt.length)
print("게시자 : ", yt.author)
print("게시날짜 : ", yt.publish_date)
print("조회수 : ", yt.views)
print("키워드 : ", yt.keywords)
print("설명 : ", yt.description)
print("썸네일 : ", yt.thumbnail_url)실행 결과
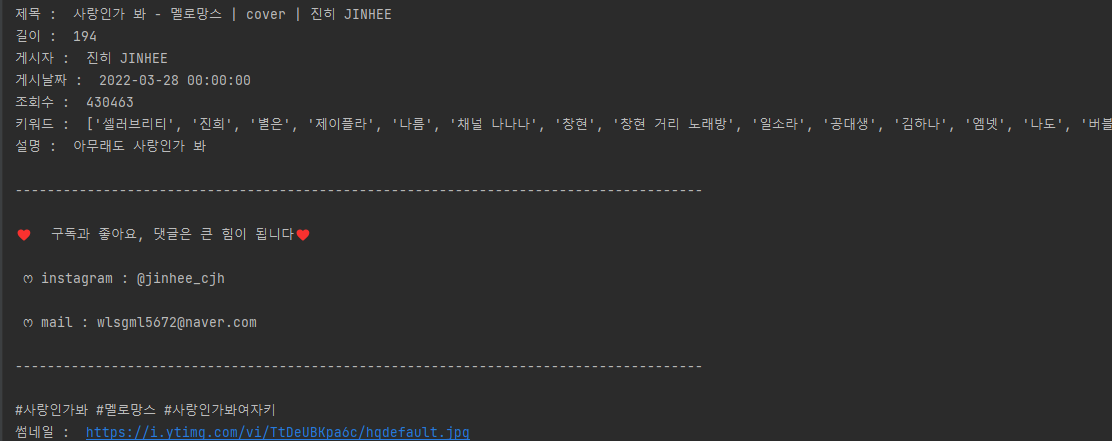
영상을 가져오고 싶은 유튜브 url을 적으면 제목, 영상길이, 조회수 등 영상 정보를 가져올 수 있습니다.
유튜브 플레이리스트에 동영상 다운로드
# 유튜브 플레이리스트 다운로드
from pytube import Playlist
playlist = 'https://www.youtube.com/playlist?list=PLbSYejIKUpAPfQtO5-xwDilxUenp3SRcd'
DOWNLOAD_DIR = r"D:\github\marinelifeirony\Python\mypytube"
p = Playlist(playlist)
for video in p.videos:
video.streams.first().download(DOWNLOAD_DIR)실행결과
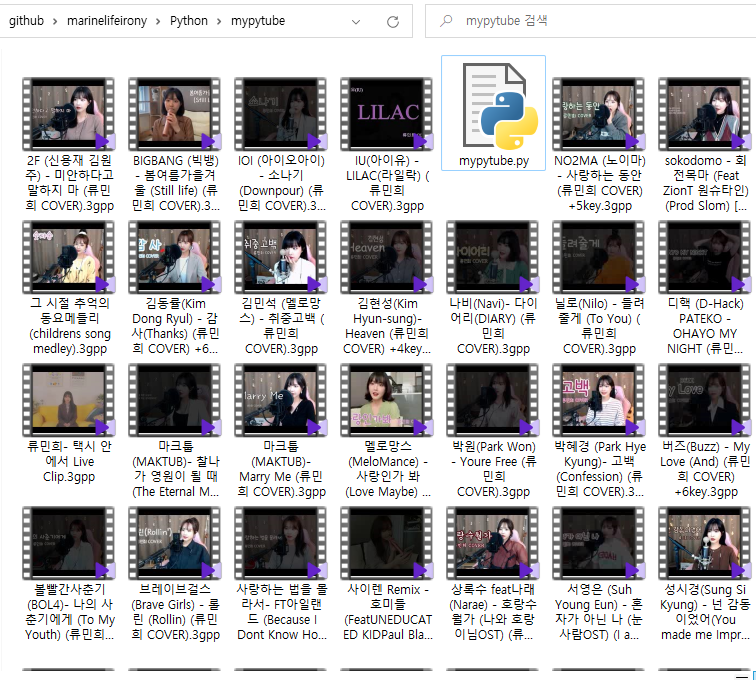
지정한 DOWNLOAD_DIR에 동영상들이 다운로드 되어진걸 확인 할 수 있습니다.
DOWNLOAD_DIR은 본인 컴퓨터 경로에 맞게 바꿔주시면 됩니다.(현재 코드는 제 컴퓨터 프로젝트 경로입니다)
Playlist를 통해 p.videos는 동영상에 차례로 접근 할수있는 iterable한 Youtube객체를 얻는것을 알 수 있습니다.그런데 다운받은 영상의 화질이 너무 낮습니다! 그 다음은 다운받을 영상의 화질을 정하는것에 대하여 알아보겠습니다.
유튜브 영상 다운로드 퀼리티
from pytube import YouTube
DOWNLOAD_DIR = r"D:\github\marinelifeirony\Python\mypytube"
url = 'https://youtu.be/TtDeUBKpa6c'
yt = YouTube(url)
for stream in yt.streams:
print(stream)
# yt.streams.get_highest_resolution().download(DOWNLOAD_DIR)
# yt.streams.get_lowest_resolution().download(DOWNLOAD_DIR)
# yt.streams.get_audio_only().download(DOWNLOAD_DIR)
video_filter = yt.streams.filter(mime_type="video/mp4", res="720p", progressive=True)
for stream in video_filter:
print(stream)yt.streams에는 사실 iterable한 stream객체들이 들어있습니다.
stream을 전체출력해보면 아래와 같은 실행결과가 나오게 됩니다.
주석 처리 되있는 부분은 pytube에서 기본적으로 제공하는 메소드 인데 get_highest_resolution(), get_lowest_resolution(), get_audio_only() 같은 메소드로 좋은 퀼리티, 나쁜 퀼리티, 오디오만 다운받을 수 있습니다.
하지만 정확히 나는 720p에 mp4확장자의 영상을 원한다고 했을때, 위처럼 filter로 원하는 형태의 비디오를 찾을 수 있습니다.(유튜브를 자주 보시는 분들은 아시겠지만 720p가 없는 최대 화질이 360p인 영상도 있기 때문에 예외처리를 해주셔야 됩니다)
실행결과의 출력물을 보고 본인이 원하는 포맷에 따라 파라미터를 주면 됩니다. 여기서 progressive=True는 영상과 소리가 같이 있는 동영상을 말합니다. False인 경우에는 영상과 소리를 따로 받을 수 있다는 소리겠지요.
실행결과
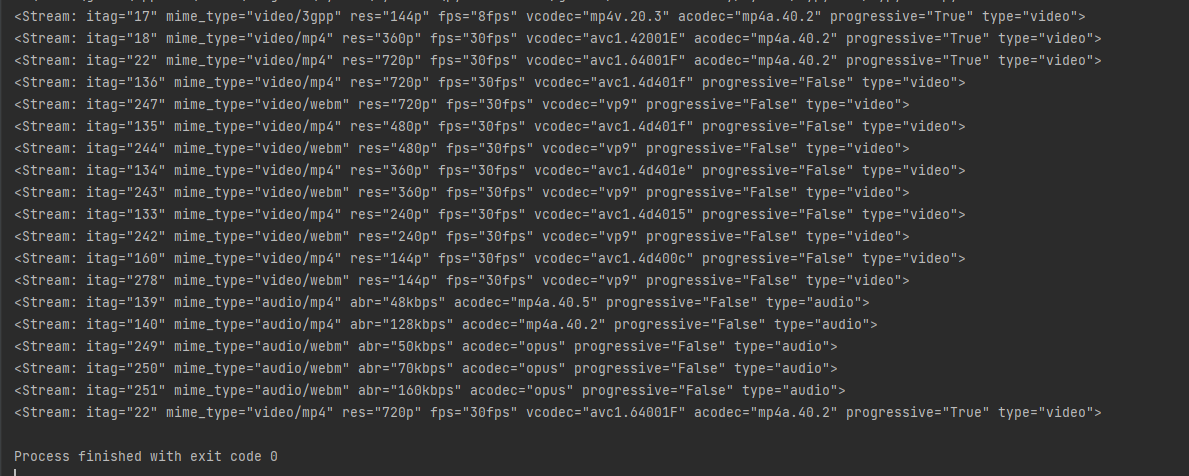
유튜브 다운로드 진행사항 출력
# 다운로드 진행사항 콜백
from pytube import YouTube
DOWNLOAD_DIR = r"D:\github\marinelifeirony\Python\mypytube"
url = 'https://youtu.be/lNDtn4wlaH0'
def on_complete(stream, file_path):
print(stream)
print(file_path)
def on_progress(stream, chunk, bytes_remaining):
print(100 - (bytes_remaining / stream.filesize * 100))
yt = YouTube(url, on_complete_callback=on_complete, on_progress_callback=on_progress)
yt.streams.first().download()
다운로드시 다운로드 진행사항을 출력하고 싶은 경우 callback 함수를 등록해주면 됩니다
Youtube 인스턴스 생성후 callback함수를 등록해주거나 바꿔주고 싶다면, register_on_complete_callback(), register_on_progress_calback() 메소드를 통해 등록해주면 됩니다.
실행결과

유튜브 영상 자막 다운받기
# 유튜브 영상 자막 다운받기
from pytube import YouTube
import re
DOWNLOAD_DIR = r"D:\github\marinelifeirony\Python\mypytube"
url = 'https://www.youtube.com/watch?v=aircAruvnKk'
yt = YouTube(url)
yt.streams.get_highest_resolution().download(DOWNLOAD_DIR)
captions = yt.captions
for caption in captions:
print(caption) # 가져올 수 있는 언어 확인
caption = captions.get_by_language_code('ko')
print(caption)
print(caption.xml_captions) # xml형태로 가져옴
srt_caption = caption.xml_caption_to_srt(caption.xml_captions) # xml -> srt
print(srt_caption)
# 해당 영상 제목에 | 특수 문자가 있다. 파일에는 특정 특수문자가 쓰여질수 없으므로 제거해줌
title = re.sub('[\/:*?"<>|]','', yt.title)
with open(DOWNLOAD_DIR + '\\' + title + '.srt', 'wt') as f:
f.write(srt_caption) # 파일로 저장yt.captions를 통해서 자막에 대한 정보에 접근 할 수 있습니다.
이 코드는 사용 가능한 언어 자막을 확인하고, 한글로 가져와서 xml형태로 출력해보고, srt형태로 변환하여 저장하는 코드입니다.
실행결과
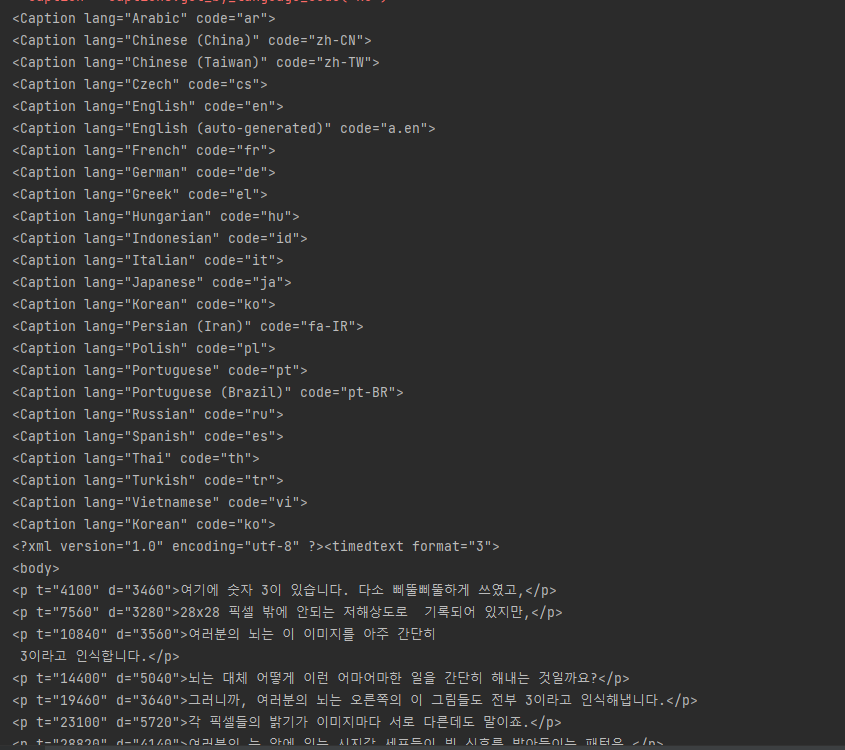
출력 결과물이 너무 길어서 짤랐습니다. 다운 받아진 영상과 자막이 제대로 실행되는지 확인해보겠습니다.

에러 해결하기

이 에러는 pytube에서 아직도 고치지 않은 에러인데, 제 환경 기준 python 3.9 pytube 12.1환경에서도 나는 에러입니다.만약 위 코드를 돌렸는데 에러가 난다면 아래에 행위를 따라해주셔야됩니다.
xml to srt conversion not working after installing pytube
I have installed pytube to extract captions from some youtube videos. Both the following code give me the xml captions. from pytube import YouTube yt = YouTube('https://www.youtube.com/watch?v=
stackoverflow.com
스택오버플로우에 적힌 응답에 의하면 유튜브에서 응답한 xml의 형태가 달라짐에 따라 그에 맞게 코드를 바꿔줘야합니다.
(여기 코드에서 수정을 좀 더 해줘야하니 아래 제가 올려둔 코드로 복붙하세요)
먼저 pytube 라이브러리에 captions.py 파일을 찾아서 수정해주어야 되는데, pycharm을 쓰시는분 기준으로 설명해드리면, ctrl을 누른상태에서 xml_caption_to_srt 메소드를 누르시면 정의로 이동 하는 기능 있습니다. 제대로 수행하셨다면 해당 파일이 열리는것을 확인 할 수 있을것입니다.
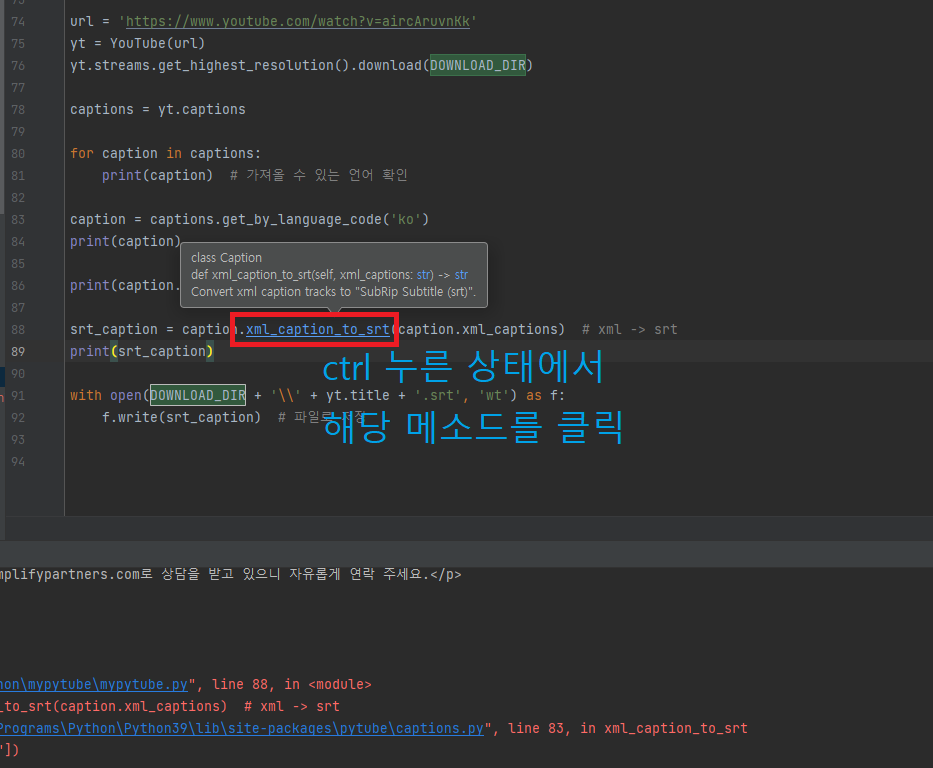
captions.py 수정(복붙해주세요)
import math
import os
import time
import xml.etree.ElementTree as ElementTree
from html import unescape
from typing import Dict, Optional
from pytube import request
from pytube.helpers import safe_filename, target_directory
class Caption:
"""Container for caption tracks."""
def __init__(self, caption_track: Dict):
"""Construct a :class:`Caption <Caption>`.
:param dict caption_track:
Caption track data extracted from ``watch_html``.
"""
self.url = caption_track.get("baseUrl")
# Certain videos have runs instead of simpleText
# this handles that edge case
name_dict = caption_track['name']
if 'simpleText' in name_dict:
self.name = name_dict['simpleText']
else:
for el in name_dict['runs']:
if 'text' in el:
self.name = el['text']
# Use "vssId" instead of "languageCode", fix issue #779
self.code = caption_track["vssId"]
# Remove preceding '.' for backwards compatibility, e.g.:
# English -> vssId: .en, languageCode: en
# English (auto-generated) -> vssId: a.en, languageCode: en
self.code = self.code.strip('.')
@property
def xml_captions(self) -> str:
"""Download the xml caption tracks."""
return request.get(self.url)
def generate_srt_captions(self) -> str:
"""Generate "SubRip Subtitle" captions.
Takes the xml captions from :meth:`~pytube.Caption.xml_captions` and
recompiles them into the "SubRip Subtitle" format.
"""
return self.xml_caption_to_srt(self.xml_captions)
@staticmethod
def float_to_srt_time_format(d: float) -> str:
"""Convert decimal durations into proper srt format.
:rtype: str
:returns:
SubRip Subtitle (str) formatted time duration.
float_to_srt_time_format(3.89) -> '00:00:03,890'
"""
fraction, whole = math.modf(d)
time_fmt = time.strftime("%H:%M:%S,", time.gmtime(whole))
ms = f"{fraction:.3f}".replace("0.", "")
return time_fmt + ms
def xml_caption_to_srt(self, xml_captions: str) -> str:
"""Convert xml caption tracks to "SubRip Subtitle (srt)".
:param str xml_captions:
XML formatted caption tracks.
"""
segments = []
root = ElementTree.fromstring(xml_captions)
for i, child in enumerate(list(root.findall('body/p'))):
text = ''.join(child.itertext()).strip()
if not text:
continue
caption = unescape(text.replace("\n", " ").replace(" ", " "),)
try:
duration = float(child.attrib['d'])
except KeyError:
duration = 0.0
start = float(child.attrib['t']) / 1000.0
end = start + duration / 1000.0
sequence_number = i + 1 # convert from 0-indexed to 1.
line = "{seq}\n{start} --> {end}\n{text}\n".format(
seq=sequence_number,
start=self.float_to_srt_time_format(start),
end=self.float_to_srt_time_format(end),
text=caption,
)
segments.append(line)
return "\n".join(segments).strip()
def download(
self,
title: str,
srt: bool = True,
output_path: Optional[str] = None,
filename_prefix: Optional[str] = None,
) -> str:
"""Write the media stream to disk.
:param title:
Output filename (stem only) for writing media file.
If one is not specified, the default filename is used.
:type title: str
:param srt:
Set to True to download srt, false to download xml. Defaults to True.
:type srt bool
:param output_path:
(optional) Output path for writing media file. If one is not
specified, defaults to the current working directory.
:type output_path: str or None
:param filename_prefix:
(optional) A string that will be prepended to the filename.
For example a number in a playlist or the name of a series.
If one is not specified, nothing will be prepended
This is separate from filename so you can use the default
filename but still add a prefix.
:type filename_prefix: str or None
:rtype: str
"""
if title.endswith(".srt") or title.endswith(".xml"):
filename = ".".join(title.split(".")[:-1])
else:
filename = title
if filename_prefix:
filename = f"{safe_filename(filename_prefix)}{filename}"
filename = safe_filename(filename)
filename += f" ({self.code})"
if srt:
filename += ".srt"
else:
filename += ".xml"
file_path = os.path.join(target_directory(output_path), filename)
with open(file_path, "w", encoding="utf-8") as file_handle:
if srt:
file_handle.write(self.generate_srt_captions())
else:
file_handle.write(self.xml_captions)
return file_path
def __repr__(self):
"""Printable object representation."""
return '<Caption lang="{s.name}" code="{s.code}">'.format(s=self)