Python 공유변수 import 할때 주의할점
필자의 경우 global_vars.py라는 파일이름으로 공유변수를 몰아놓고 사용하는데
공유변수를 따로 빼놓음으로써 함수에 전달되는 파라미터 수를 줄이고, 모듈간에 순환참조를 예방할수 있다는 이점을 가져갈수 있다.
공유변수 import '~' 방식
a.py와 b.py에서 모두 쓰는 공유변수를 c.py에 몰아넣는다고 해보자
a.py
a = 10
a_dict = {'a': 10}
a_list = [1, 2, 3]
class __a_class:
a = 10
a_class = __a_class()b.py
import a
def b():
return a.a
def b_dict():
return a.a_dict
def b_list():
return a.a_list
def b_class():
return a.a_classc.py
import a
import b
a.a = 22
print(f'일반자료형 - {a.a}, {b.b()}')
print(f'일반자료형id - {id(a.a)}, {id(b.b())}')
a.a_dict['c'] = 22
print(f'딕셔너리 - {a.a_dict}, {b.b_dict()}')
a.a_list.append(22)
print(f'리스트 - {a.a_list}, {b.b_list()}')
a.a_class.a = 22
print(f'인스턴스객체 - {a.a_class}, {b.b_class()}')
print(f'인스턴스객체필드값 - {a.a_class.a}, {b.b_class().a}')결과

정상적으로 c.py에서 수정한 내역이 b.py에게도 영향을 미친다
공유변수 from '~' imoprt `~' 방식
from '~' import '~' 방식으로 수정한 c.py
from a import a, a_dict, a_list, a_class
from b import b, b_dict, b_list, b_class
a = 22
print(f'일반자료형 - {a}, {b()}')
print(f'일반자료형id - {id(a)}, {id(b())}')
a_dict['c'] = 22
print(f'딕셔너리 - {a_dict}, {b_dict()}')
a_list.append(22)
print(f'리스트 - {a_list}, {b_list()}')
a_class.a = 22
print(f'인스턴스객체 - {a_class}, {b_class()}')
print(f'인스턴스객체필드값 - {a_class.a}, {b_class().a}')그럼 from import 방식으로 가져온 값들도 마찬가지의 결과를 보여줄까?

이상하게도 일반자료형인 a에 대해서는 값을 수정하는것에 대한 보장을 받지 못하는 모습이다.
심지어 c.py에서의 a와 b.py에서의 a는 id값이 다른변수로 인식되고 있다..
그에 반면 일반자료형이 아닌 객체형태의 자료형은 같은 여전히 같은 결과를 보여주고 있다
왜 이런일이 발생하는걸까?
파이참ide에서 보면 from a import a를 통해 가져온 일반변수 a보다 c.py에 a = 22라고 선언된 글로벌 변수보다 우선순위가 밀린것을 알 수있다(그저 새로운값을 할당하려 했던거뿐인데..)
즉 파이썬에서 해당방식으로 변수를 가져오는 경우 스코프의 문제로 일반변수는 타스크립트에서 우선권을 가져가지 못해 우리가 생각했던대로 공유변수를 쓸수 없다.
b.py스크립트에서 a를 고친다면?
그럼 c.py에서 글로벌 변수 a를 따로 선언하지 않고 b.py에서 a변수를 수정하는 책임을 넘기는 경우에 우리가 원하는 대로 작동할까?
setter추가한 b.py
import a
def b():
return a.a
def b_setter():
a.a = 22
def b_dict():
return a.a_dict
def b_list():
return a.a_list
def b_class():
return a.a_class
setter적용한 c.py
from a import a, a_dict, a_list, a_class
from b import b, b_dict, b_list, b_class, b_setter
b_setter()
print(f'일반자료형 - {a}, {b()}')
print(f'일반자료형id - {id(a)}, {id(b())}')
a_dict['c'] = 22
print(f'딕셔너리 - {a_dict}, {b_dict()}')
a_list.append(22)
print(f'리스트 - {a_list}, {b_list()}')
a_class.a = 22
print(f'인스턴스객체 - {a_class}, {b_class()}')
print(f'인스턴스객체필드값 - {a_class.a}, {b_class().a}')결과

이번엔 c.py스코프에 a라는 글로벌 변수가 따로 없었기 때문에 from a import a의 값을 그대로 가져다 출력하였다.
그런데 그럼에도 불구하고 b_setter()결과가 정상적으로 적용되지 않고 id값마저 다르다
그럼 b_setter()를 지우고 실행하면 어떻게 될까?
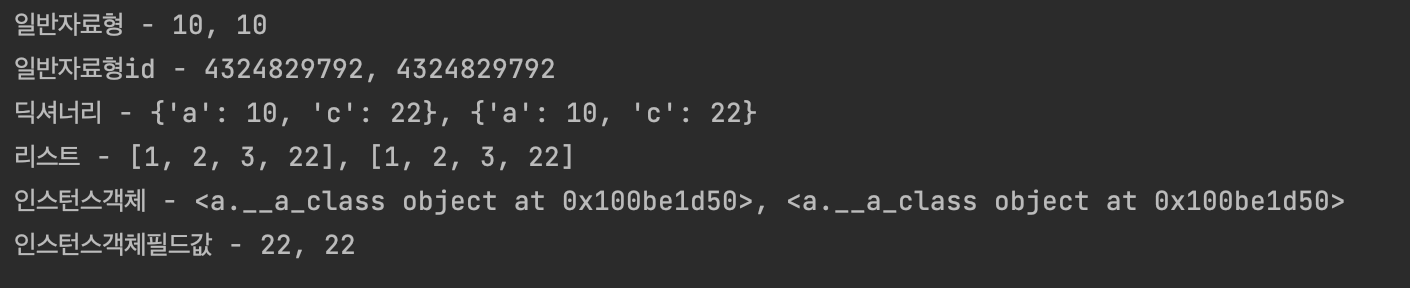
ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ 아놔.. 같은 id를 반환한다.. 인터프리터에서 최적화하는건지.. 수정하지 않으면 같은id를 반환하는 원인은 정확히 모르겠다
결론
번외로 a.py에서 a_setter함수를 만들어서 사용한다 하더라도 결과는 같다
결론은 일반공유변수를 사용할때 인터프리터가 스코프 인식을 제대로 하지 못하는 from '~' import '~' 방식보단 import '~'을 사용하는 것을 권장하고 그래도 전자의 방식이 편하다면 공유변수를 관리하는 객체를 따로 하나 선언해서 인스턴스를 만들어서 공유해야한다.
그렇지 않으면 인터프리터에서 자체참조를하여 변수 사본을 만들기 때문에 생각했던대로 공유변수처럼 쓸수 없다
이 차이를 모르고 짜서 버그났던 코드나 갈아엎으로 가야겠다...