
1. 데이터베이스 정의
* 한 조직의 여러 응용 시스템들의 공용하기 위해 통합, 저장한 운영 데이터의 집합
데이터베이스의 정의
데이터베이스는 특정 조직의 업무를 수행하는 데 필요한 상호 관련된 데이터들의 모임이다.
1. 통합된 데이터(Integrated Data): 자료의 중복을 배제한 데이터의 모임이다.
2. 저장된 데이터(Stored Data): 컴퓨터가 접근할 수 있는 저장 매체에 저장된 자료이다.
3. 운영 데이터(Operational Data): 조직의 고유한 업무를 수행하는 데 존재 가치가 확실하고 없어서는 안 될 반드시 필요한 자료이다.
4. 공용 데이터(Shared Data): 여러 응용 시스템들이 공동으로 소유하고 유지하는 자료이다.
데이터베이스의 특징
1. 실시간 접근성(Real-Time Accessibility): 수시적이고 비정형적인 질의(조회)에 대하여 실시간 처리에 의한 응답이 가능해야 한다.
2. 계속적인 변화(Continuous Evolution): 데이터베이스의 상태는 동적이다. 즉 새로운 데이터의 삽입(Insert),삭제(Delete),갱신(Update)로 항상 최신의 데이터를 유지한다.
3. 동시공용(Concurrent Sharing): 데이터베이스는 서로 다른 목적을 가진 여러 응용자들을 위한 것이므로 다수의 사용자가 동시에 같은 내용의 데이터를 이용할 수 있어야 한다.
4. 내용에 의한 참조(Content Reference): 데이터베이스에 있는 데이터를 참조할 때 데이터 레코드의 주소나 위치에 의해서가 아니라, 사용자가 요구하는 데이터 내용으로 데이터를 찾는다.
2. 파일 기반의 데이터 처리 시스템에서 야기되는 문제 기술

파일들이 프로그램에 종속되어 데이터 구성 방법이나 접근 방법의 변경 시 관련 응용 프로그램도 동시에 변경해야 된다. (데이터의 종속성) 같은 데이터가 여러 파일에 중복되어 저장되는 것을 관리할 수 없다. (데이터의 중복성 – 일관성, 보안성, 경제성, 무결성)
중복성으로 인한 문제점
일관성: 중복된 데이터 간에 내용이 일치하지 않는 상황이 발생하여 일관성이 없어진다.
보안성: 중복되어 있는 모든 데이터에 동등한 보안수준을 유지하기가 어렵다.
경제성: 저장공간의 낭비와 동일한 데이터의 반복 작업으로 비용이 증가한다.
무결성: 제어의 분산으로 데이터의 정확성을 유지할 수 없다.
3. 데이터독립성이란? 그리고, 데이터 독립성에 대해 3단계간의 사상(Mapping)과 연계하여 그림을 그리고 설명하기
데이터 독립성이란 특정 스키마를 변경해도 상위 수준의 스키마 정의에 영향을 주지 않는 성질을 말한다. 데이터베이스의 새로운 데이터가 추가되거나 필드가 추가/삭제된다 하더라도 응용프로그램에서 사용자의 뷰에서 직접 관련되지 않는 부분들은 영향을 받지 않는다. 물리적 스키마 구조가 바뀌더라도 개념스키마나 사용자가 이용하는 응용프로그램은 영향을 받지 않는다.
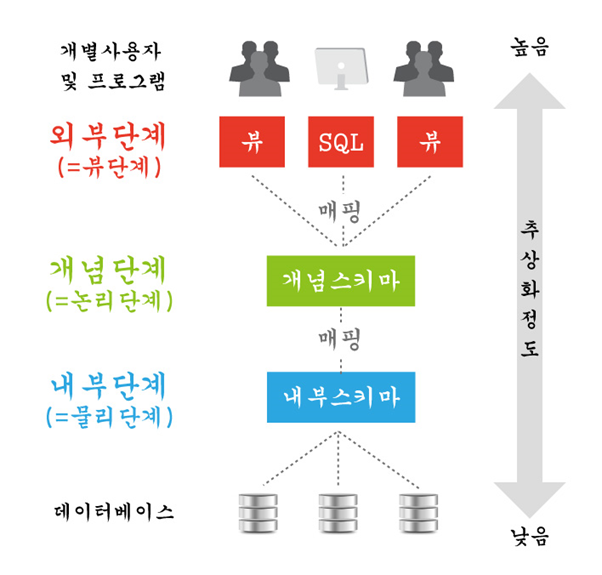
외부 스키마(사용자 뷰) – 데이터베이스의 개인 사용자나 응용 프로그래머가 접근하는 데이터베이스를 정의한 것이다.
개념 스키마(전체적인 뷰) – 범 기관적 입장에서 데이터베이스를 정의한 것이다. (그냥 스키마) 모든 데이터의 개체, 관계 제약조건 등을 포함 및 관리하는데 필수정보인 접근 권한, 보안정책, 무결성 규칙에 대한 명세도 포함된다.
내부 스키마(저장스키마) – 저장 장치 입장에서 전체 데이터베이스가 저장되는 방법을 명세한 것이다.

외부/개념 사상(논리적사상) – 응용 프로그램을 변경시키지 않고도 개념 스키마를 변경 시킬 수 있으므로, 결과적으로 논리적 데이터 독립성을 제공해 준다.
개념/내부 사상 (물리적 사상, 저장 인터페이스) – 개념 스키마에 아무런 영향을 주지 않게 되고 응용 프로그램에도 아무런 영향을 주지 않게 되므로 물리적 데이터 독립성을 제공해 준다.
4. 데이터베이스관리시스템의 장단점
DBMS란? 응용 프로그램과 데이터 사이의 중재자로서 모든 응용프로그램들이 데이터베이스를 공용할 수 있게 관리해 주는 범용 소프트웨어 시스템이다.
장점
l 데이터의 논리적 물리적 독립성이 보장된다.
l 데이터의 중복을 피할 수 있어 기억공간이 절약된다.
l 저장된 자료를 공동으로 이용할 수 있다.
l 데이터의 일관성을 유지할 수 있다.
l 데이터의 무결성을 유지할 수 있다.
l 보안을 유지할 수 있다.
l 데이터를 표준화할 수 있다.
l 데이터를 통합하여 관리할 수 있다.
l 항상 최신의 데이터를 유지한다.
l 데이터의 실시간 처리가 가능하다.
단점
l 운영비의 overhead(전문가가 필요, 전산비용 증가)
l 특정 응용 프로그램의 복잡화
l 복잡한 backup과 recovery
l 시스템의 취약성
5. 데이터베이스관리시스템의 필수 기능 3가지
1. 정의기능 – 하나의 저장 구조로 여러 사용자의 요구를 지원할 수 있도록 데이터의 형(Type)과 구조에 대한 정의, 이용 방식, 제약 조건 등을 명시하는 기능이다
2. 조작기능 – 데이터 검색, 갱신, 삽입, 삭제 등을 체계적으로 처리하기 위해 사용자와 데이터베이스 사이의 인터페이스 수단을 제공하는 기능이다
3. 제어기능 – 데이터베이스를 접근하는 갱신, 삽입, 삭제 작업이 정확하게 수행되어 데이터의 무결성이 유지되도록 제어해야 된다. 정당한 사용자가 허가된 데이터에 접근할 수 있도록 보안을 유지하고 권한을 검사할 수 있어야 한다.
6. 데이터 베이스 언어란? (DDL, DML, DCL)
데이터베이스 언어는 데이터베이스를 구축하고 이용하기 위한 데이터베이스 시스템과 통신 수단이다. DBMS를 통해 사용 되며, 기능과 사용 목적에 따라 데이터 정의 언어, 데이터 조작 언어, 데이터 제어 언어로 구분된다.
데이터 정의 언어(DDL)
1. 데이터 정의 언어(DDL)는 DB구조, 데이터 형식, 접근 방식 등 DB를 구축하거나 수정할 목적으로 사용하는 언어이다.
2. 데이터 정의 언어는 번역한 결과가 데이터 사전(DataDictionary)이라는 특별한 파일에 여러개의 테이블로서 저장된다.
데이터 정의 언어(DDL)의 기능
1. 외부 스키마 명세를 정의한다.
2. 데이터베이스의 논리적, 물리적 구조 및 구조 간의 사상을 정의한다.
3. 스키마에 사용되는 제약 조건에 대한 명세를 정의한다.
4. 데이터의 물리적 순서를 규정한다.
데이터 정의 언어(DDL) 예제
1. CREATE
2. DROP
3. ALTER
데이터 조작언어(DML)
1. 데이터 조작 언어(DML)는 사용자로 하여금 데이터를 처리할 수 있게 하는 도구로서, 사용자(응용 프로그램)와 DBMS 간의 인터페이스를 제공한다.
2. 응용프로그램을 통하여 사용자가 DB의 데이터를 실질적으로 조작할 수 있도록 하기 위해 다양한 언어에 DB기능을 추가해서 만든 언어이다.
3. 대표적인 데이터 조작 언어(DML)에는 질의어가 있으며, 질의어는 터미널에서 주로 이용하는 비절차적(Non Procedural)데이터 언어이다.
※ 질의어란 : 단말 사용자가 쉽게 DB를 액세스할 수 있도록 대화식의 자연어로 만든 비절차적 조작언어이다. 독자적이고 상호 작용 형태로 터미널에서 많이 사용하는 고급 명령어 형태의 독립된 데이터 조작언어이다.
데이터 조작어의 조건
1. 사용하기 쉽고 자연언어에 가까워야한다.
2. 데이터에 대한 연산뿐만 아니라 뷰 내의 데이터나 데이터 간의 관계를 정확하고 완전하게 명시할 수 있어야 한다.
3. 데이터 언어의 효율적인 구현을 지원해야 한다. 즉 데이터 언어의 구문이 DBMS가 제공하는 기본적인 연산과 관련을 갖도록 해야 한다.
데이터 제어 언어(DCL)
1. 데이터 제어 언어(DCL)는 무결성, 보안 및 권한 제어 회복 등을 하기 위한 언어이다.
2. 데이터 제어 언어(DCL)는 데이터를 보호하고 데이터를 관리하는 목적으로 사용된다.
데이터 제어 언어의 기능
1. 불법적인 사용자로부터 데이터를 보호하기 위한 데이터 보안(Security)
2. 데이터 정확성을 위한 무결성(Integrity)유지
3. 시스템 장애에 대비한 회복과 병행수행 제어
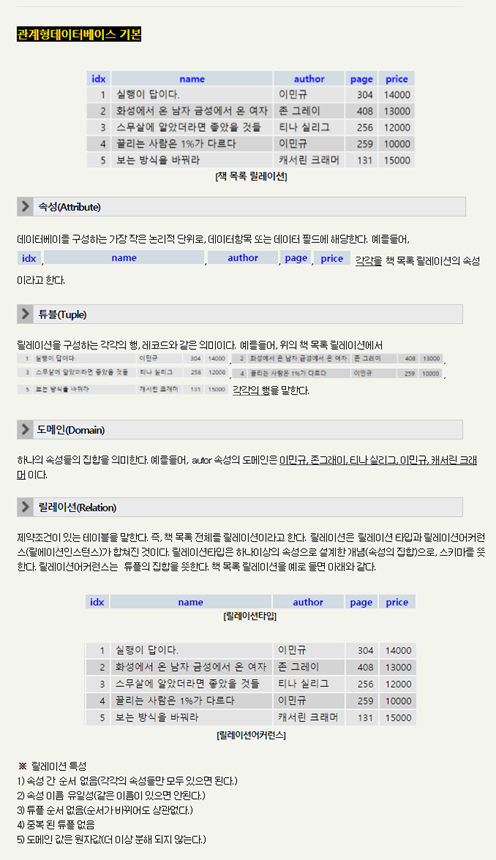
7. 관계형 데이터베이스 구성

8. 데이터베이스 키의 종류와 개념
키(Key)란? : 키는 데이터베이스에서 조건에 만족하는 튜플을 찾거나 순서대로 정렬할 때 튜플들을 서로 구분할 수 있는 기준이 되는 애트리뷰트를 말한다.
후보키(Candidate Key)
1. 후보키는 릴레이션을 구성하는 속성들 중에서 튜플을 유일하게 식별하기 위해 사용하는 속성들의 부분집합, 즉 기본키로 사용할 수 있는 속성들을 말한다.
2. 하나의 릴레이션내에서는 중복된 튜플들이 있을 수 없으므로 모든 릴레이션에는 반드시 하나 이상의 후보키가 존재한다.
3. 후보키는 릴레이션에 있는 모든 튜플에 대해서 유일성과 최소성을 만족시켜야 한다.
유일성: 하나의 키값으로 하나의 튜플만을 유일하게 식별할 수 있어야한다.
최소성: 모든 레코드들을 유일하게 식별하는데 꼭 필요한 속성만으로 구성되어 있어야한다.
기본키(Primary Key)
1. 기본키는 후보키 중에서 선택한 주키(Main Key)이다.
2. 한 릴레이션에서 특정 튜플을 유일하게 구별할 수 있는 속성이다.
3. Null값을 가질 수 없다.
4. 기본키로 정의된 속성에는 동일한 값이 중복되어 저장될 수 없다.
대체키(Alternate Key)
1. 후보키가 둘 이상일 때 기본키를 제외한 나머지 후보키들을 말한다.
2. 보조키라고도 한다.
슈퍼키(Super Key)
1. 슈퍼키는 한 릴레이션 내에 있는 속성들의 집합으로 구성된 키로서 릴레이션을 구성하는 모든 튜플들 중 슈퍼키로 구성된 속성의 집합과 동일한 값을 나타나지 않는다.
2. 슈퍼키는 릴레이션을 구성하는 모든 튜플에 대해 유일성을 만족시키지만, 최소성은 만족시키지 못한다.
최소성: 학번 + 주민번호를 사용하여 슈퍼키를 만들면 다른 튜플들과 구분할 수 있는 유일성은 만족하지만 학번이나 주민번호 하나만 가지고도 다른 튜플들을 구분할 수 있으므로 최소성은 만족시키지 못한다.
외래키(Foregin Key)
1. 관계를 맺고 있는 릴레이션 R1,R2에서 릴레이션 R1이 참조하고 있는 릴레이션 R2의 기본키와 같은 R1 릴레이션의 속성을 외래키라고 한다.
2. 외래키는 참조되는 릴레이션의 기본키와 대응되어 릴레이션 간에 참조관계를 표현하는데 중요한 도구이다.
9. 무결성 제약조건 의미 종류 설명
1. 무결성과 데이터 무결성
가. 무결성: 데이터 및 네트워크 보안에 있어서 정보가 인가된 사람에 의해서만 접근이나 변경이 가능한 성질
(IT분야에서 사용하는 용어)
나. 데이터 무결성: 데이터를 인가되지 않은 방법으로 변경할 수 없도록 보호하는 성질
(데이터베이스 분야에서 사용되는 용어)
2. 물리적 무결성 제약조건과 의미적 무결성 제약조건
가. 물리적 무결성 제약 조건
1) 데이터 모델 내부에서 정의되고, 주로 데이터의 구조나 이에 적용되는 연산의 물리적 특성을 제약하는 조건
나. 의미적 무결성 제약조건
1) 데이터베이스 설계자가 외부 시키마를 정의할 때 해당 데이터베이스가 실세계를 정확히 반영하도록 하기 위해서 데이터베이스
안에 의미에 관한 정보를 규정하도록 하는 제약 조건
3. 관계 데이터 모델의 무결성 제약 조건 종류
가. 개체 무결성 제약 조건 (enity integrity constraint)
나. 참조 무결성 제약 조건 (referential integrity constraint)
다. 도메인 무결성 제약 조건 (domain integrity constraint)
라. 사용자 정의 무결성 제약 조건 (user define integrity constraint)
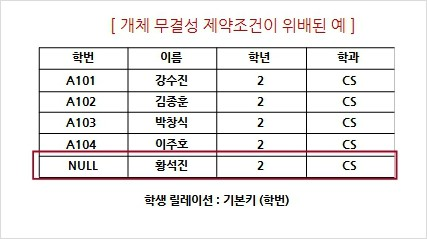
4. 개체 무결성 제약 조건
가. 하나의 릴레이션에서 기본키로 지정된 모든 튜플의 속성은 항상 널 값을 가질 수 없다는 조건
나. 개체 무결성 제약 조건으로 인해 릴레이션의 모든 튜플들에 대해 유일성을 보장 할 수 있다.
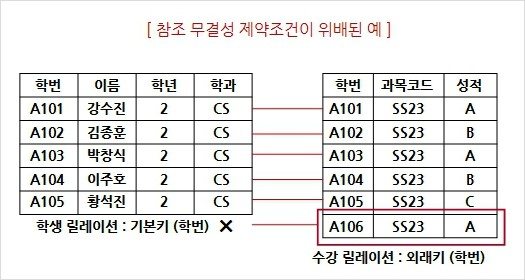
4. 참조 무결성 제약 조건
가. 릴레이션과 릴레이션 사이에 대해 참조의 일관성을 보장하기 위한 조건
나. 두개의 릴레이션이 기본키, 외래키를 통해 참조 관계를 형성할 경우, 참조하는 외래키의 값은 항상 참조되는
릴레이션에 기본키로 존재해야 한다.
다. 참조 무결성 제약조건을 만족시키기 위해서 DBMS가 제공하는 옵션
1) 제한
- 위배를 야기한 연산을 단순히 거절
- 예 : DEPARTMENT릴레이션에서 (2, 개발, 9)를 삭제하면 참조 무결성 제약조건을 위배하게 되므로 삭제 연산을 거절
2) 연쇄
- 참조되는 릴레이션에서 튜플을 삭제하고, 참조하는 릴레이션에서 이 튜플을 참조하는 튜플들도 함께 삭제
- 예 : DEPARTMENT릴레이션에서 (3,개발,9)를 삭제하면 EMPLOYEE릴레이션에서 부서번호 3을 참조하는 두 번째
튜플과 다섯 번째 튜플도 함께 삭제

3) 널값
- 참조되는 릴레이션에서 튜플을 삭제하고, 참조하는 릴레이션에서 이 튜플을 참조하는 튜플들의 외래 키에 NULL값을 삽입
- 예 : DEPARTMENT릴레이션에서 (3,개발,9)를 삭제하면 EMPLOYEE릴레이션에서 부서번호 3을 참조하는 두번째 튜플과
다선번째 튜플의 부서번호에 NULL값을 삽입
4) 기본값
- NULL값을 넣는 대신에 DEFAULT값을 넣는 다는 것을 제외하고는 바로 위에 널값 옵션과 동일함

5. 도메인 무결성 제약 조건
가. 도메인 무결성 제약조건은 다른 리레이션과 관계없이 속성자체에만 적용되는 제약조건이다.
나. 모든 속성은 특정한 도메인으로 정의되므로 해당 속성은 도메인에 존재하는 값만 가질 수 있다.
다. 튜플을 삽입하거나 갱신하는 경우 튜플안의 모든 속성은 각각의 도메인 집합 안에 존재하는 값을 취해야 하는 것이
도메인 무결성 제약 조건이다.
6. 사용자 정의 제약조건
가. 사용자가 다른 무결성 범주에 포함되지 않는 특정 업무 규칙을 정의하여 사용하는 것
나. 모든 범주의 무결성 제약조건은 사용자 정의 무결성 제약 조건을 지원한다.
10. 일반 집합 연산자와 합병 가능 조건
일반 집합 연산자
- 집합 연산은 수학적 집합 이론에서 사용하는 연산자로 릴레이션 연산에도 그대로 적용할 수 있다.
- 집합 연산 중 UNION, DIFFERENCE, INTERSECTION을 처리하기 위해서는 합병 조건을 만족해야한다.
※ 합병 조건: 합병하려는 두 릴레이션 간에 속성의 수가 같고, 대응되는 속성별로 도메인이 같아야한다. 즉, 릴레이션 R과 S가 합병 가능하다면, 릴레이션 R의 i번째 속성과 릴레이션 S의 i번째 속성의 도메인이 서로 같아야 한다. 속성의 이름이 같아야되는 것은 아님.
- 두 릴레이션 R과 S가 있을 때 각 집합 연산의 특징

11. 순수 관계연산자 – SELECT, PROJECT, JOIN, DIVISION
SELECT
- 릴레이션에 존재하는 튜플들 중에서 특정 조건을 만족하는 튜플들의 부분집합을 구하여 새로운 릴레이션을 만든다.
- 릴레이션의 행에 해당하는 튜플을 구하는 것으로, 수평 연산이라고도 한다.
- SELECT 연산의 기호는 그리스 문자 시그마(σ)이다.
- 표기 형식: σ(조건)(R)
· R은 릴레이션
· 조건에서는 =, ≠, <, ≤, >, ≥ 등의 기호를 사용한 비교 연산이 허용, AND(∧), OR(∨), NOT(ㄱ) 등의 논리 연산자를 사용하여 여러 개의 조건들을 하나의 조건으로 결합시킬 수도 있다.
PROJECT
- 주어진 릴레이션에서 속성 리스트에 제시된 속성 값만을 추출하여 새로운 릴레이션을 만든다. 단, 연산 결과에 중복이 발생하면 중복이 제거된다.
- 릴레이션에서 열에 해당하는 속성을 추출하는 것으로, 수직 연산이라고도 한다.
- PROJECT 연산의 기호는 그리스 문자 파이(π)이다.
- 표기 형식: π(속성 리스트)(R)
· R은 릴레이션
JOIN
- 공통 속성을 중심으로 2개의 릴레이션을 하나로 합쳐서 새로운 릴레이션을 만든다.
- JOIN 연산의 결과로 만들어진 릴레이션의 차수는 조인된 두 릴레이션의 차수를 합한 것과 같다.
- JOIN 연산의 결과는 CARTESIAN PRODUCT 연산을 수행한 다음 SELECT 연산을 수행한 것과 같다.
- JOIN 연산의 기호는 ▷◁ 이다.
- 표기 형식: R▷◁(JOIN 조건)S
· R, S는 릴레이션
· =, ≠, <, ≤, >, ≥ 등의 비교 연산자를 비교 연산자를 θ로 일반화하여 θ로 표현될 수 있는 조인을 세타 조인(θ-join, Theta JOIN)이라고 한다.
· JOIN 조건이 '='일 때 동일한 속성이 2번 나타나게 되는데, 이 중 중복된 속성을 제거하여 같은 속성은 1번만 나타나게 하는 연산을 자연 조인(NATURAL JOIN)이라고 한다.
· 자연 조인과 반대로 중복된 속성을 나타내는 연산은 동일 조인(Equi JOIN)이다.
DIVISION
- 두 릴레이션 R(X)과 S(Y)에 대해 Y⊆X, X-Y=Z라고 하면, R(X)와 R(Z,Y)는 동일한 표현이다. 이때, 릴레이션 R(Z,Y)에 대한 S(Y)의 DIVISION 연산은 S(Y)의 모든 튜플에 연관되어 있는 R(Z)의 튜플을 선택하는 것이다.
- 표기 형식: R[속성r ÷ 속성s]S
· 속성 r은 릴레이션 R의 속성, 속성 s는 릴레이션 S의 속성이며, 속성 r과 s는 동일 소성 값을 가지는 속성이어야 한다.
12. 복합연산을 기본연산으로 표현

13. 세타조인, 동일조인, 자연조인의 설명

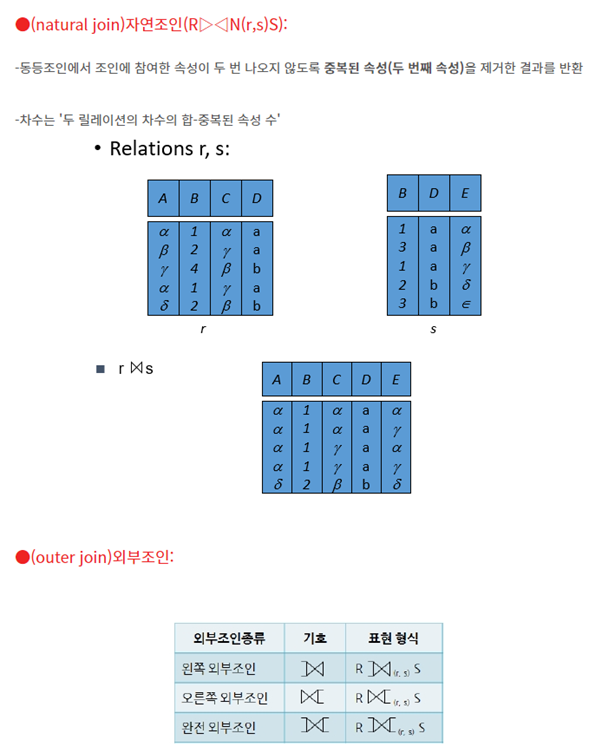

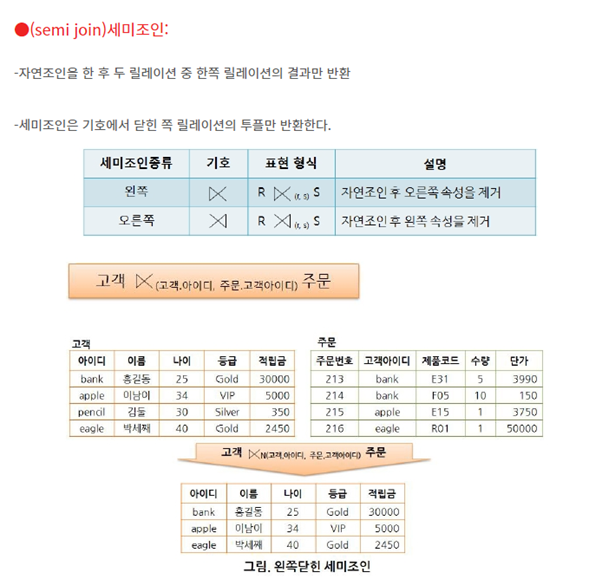
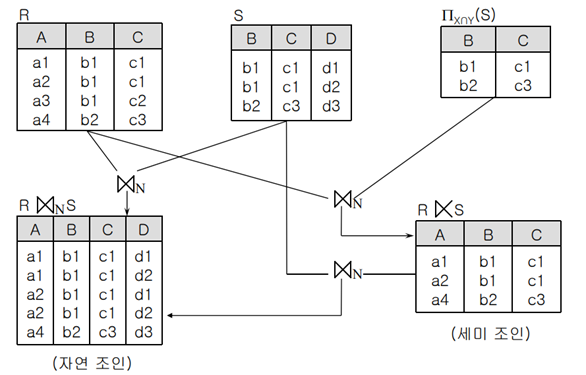
15. 세미 조인에 대해 (1) 세미조인 사용하는 이유, (2) 조인과 프로젝트를 이용하여 표현, (3) 세미조인 처리 결과
1) 해당하는 row를 찾으며 다른 row를 더이상 조회하지 않으므로 모든 row를 읽어들이는 inner join보다 성능이 향상된다. 그리고 group by나 distinct에서 한번 더 소모되던 비용을 줄여준다.

16. ROLLBACK, COMMIT
오라클에서는 작업이 끝난 후 commit;을 해줘야 DML언어를 사용하여 했던 작업을 모두 처리한다.
COMMIT
- 모든 작업을 정상적으로 처리하겠다고 확정하는 명령어이다.
- 트랜젝션의 처리 과정을 데이터베이스에 반영하기 위해서, 변경된 내용을 모두 영구 저장한다.
- COMMIT 수행하면, 하나의 트랜젝션 과정을 종료하게 된다.
- TRANSACTION(INSERT, UPDATE, DELETE)작업 내용을 실제 DB에 저장한다.
- 이전 데이터가 완전히 UPDATE된다.
- 모든 사용자가 변경한 데이터의 결과를 볼 수 있다.
Rollback 명령어는 commit하기 이전의 상태로 복구하기 위한 명령어이다.
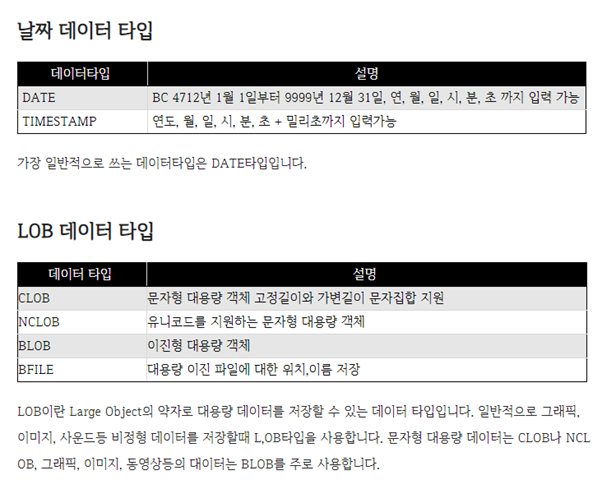
17. SQL(ORACLE)









'기타' 카테고리의 다른 글
| 비트코인(가상화폐)에 대한 나의 생각 정리 (2) | 2021.06.22 |
|---|---|
| 국제통상의 기초와 이해 (제2판) - 이상직 해답 (0) | 2021.06.19 |
| 합격으로 이끄는 단순하지만 결정적인 비법 (0) | 2021.03.12 |
| 내 최애캐릭터 menhara-chan 사진 모음 (0) | 2021.02.15 |
| 기독교 혹은 종교에 대한 생각 (2) | 2018.02.08 |